hard notes
hard benchmark design notes
Background notes for the Hard leaderboard: problem ceilings, known caveats, and the FP8 constraint rerun. The operational leaderboard lives on /hard.
per-problem ceilings
eager / compiled = PyTorch reference timings. SOTA = the existing best-known kernel for the problem when one exists on this hardware. best peak = the model that pushed furthest above the reference line.
| problem | eager ms | compiled ms | SOTA ms | best peak | best model | n scored |
|---|---|---|---|---|---|---|
| FP8 GEMM | 0.472 | 0.438 | - | 0.406 | zai-claude/glm-5.2 | 11/11 |
| KDA CUTLASS | 61.893 | 7.425 | - | 0.055 | claude/claude-opus-4-8 | 8/10 |
| Paged Attention | 1.262 | 1.274 | - | 0.677 | zai-claude/glm-5.2 | 10/10 |
| TopK Bitonic | 0.041 | 0.077 | 0.041 | 0.095 | or-opus/anthropic/claude-opus-5 [max] | 10/11 |
| Sonic MoE SwiGLU | 9.688 | 9.753 | - | 0.105 | or-fable/anthropic/claude-fable-5 | 9/10 |
| W4A16 GEMM | 0.605 | 0.144 | - | 0.373 | kinetic-claude/kinetic-0715 | 12/13 |
rubric caveat
01 fp8_gemm: bf16 dressup
Every passing solution at peak >= 0.4 casts the fp8 inputs to bf16 inside the kernel and runs a bf16 GEMM. The peak fractions on this row reflect bf16 GEMM optimization quality on fp8-typed inputs, not FP8 tensor core skill.
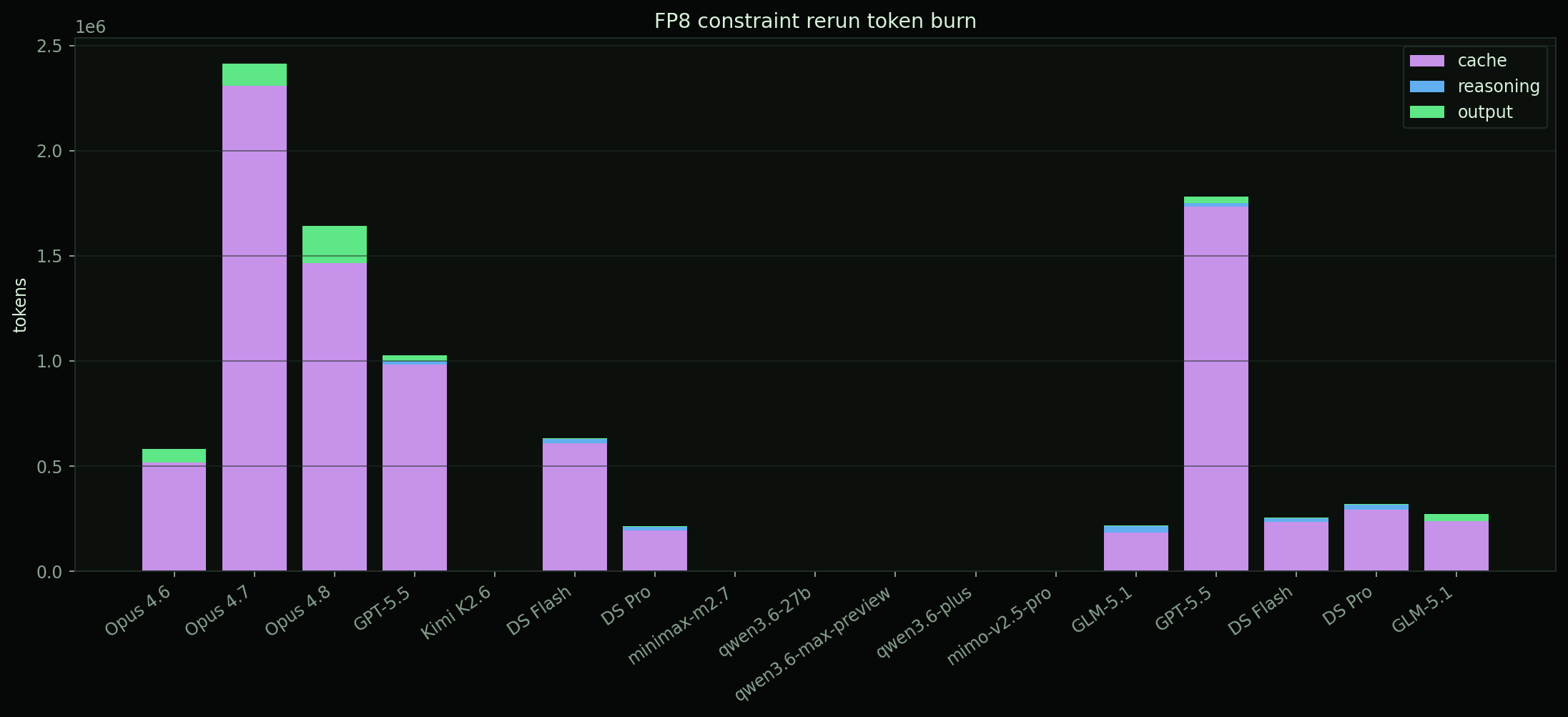
fp8 constraint rerun
On June 5, 2026, the FP8 GEMM verifier was tightened to reject the bf16-dressup shortcut and require an FP8-looking execution path. Once the shortcut was blocked, every available model either failed correctness, failed the provider path, or could not run because of credits/key issues.
fixed-tolerance rerun
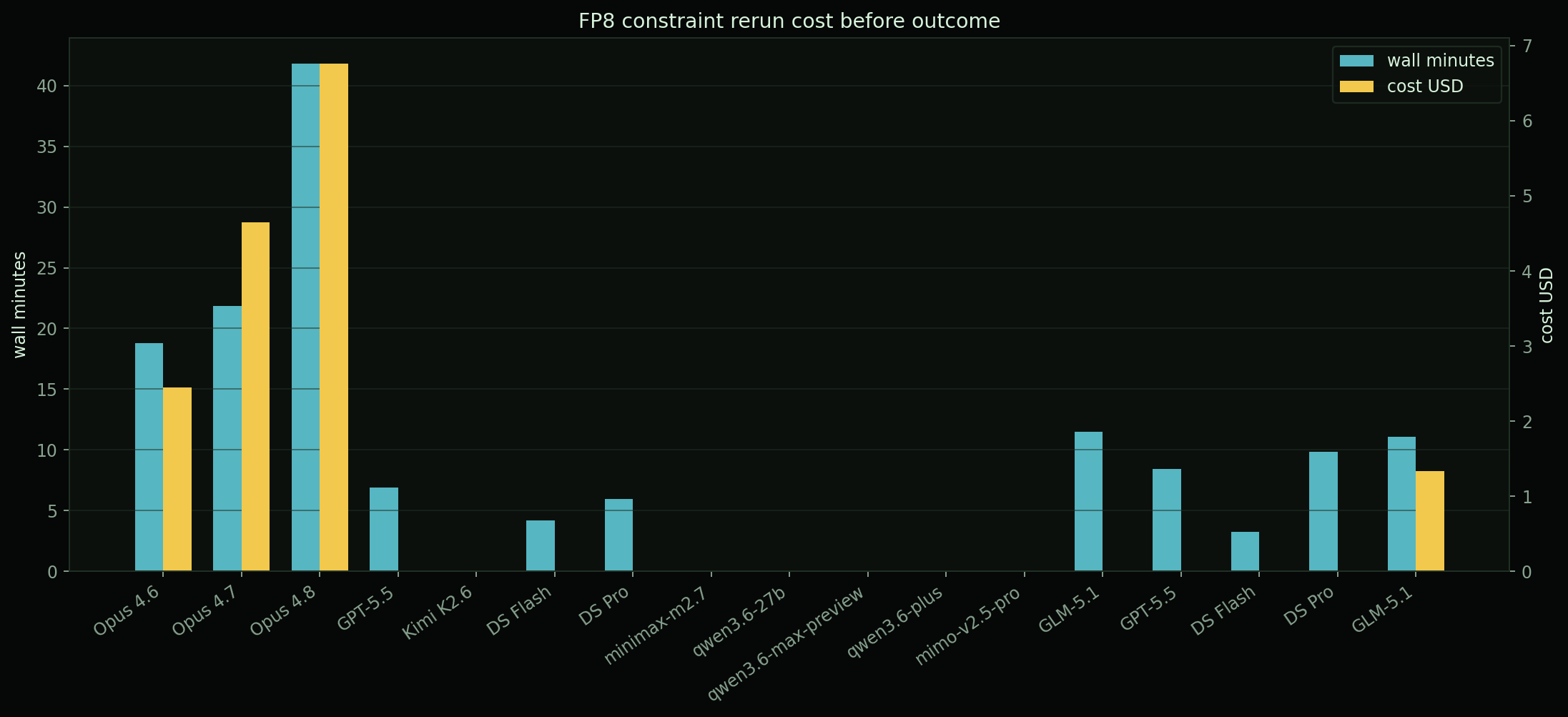
| model | route | outcome | elapsed | note |
|---|---|---|---|---|
| Claude Opus 4.6 | claude | FAIL | 18.5m | large_input stress failed, max_abs_diff=4 |
| Claude Opus 4.7 | claude | FAIL | 21.6m | check_failed under real FP8 constraint |
| Claude Opus 4.8 | claude | FAIL | 41.8m | large_input K=4127 failed, max_abs_diff=4 |
| GPT-5.5 | codex | FAIL | 6.8m | nominal tolerance failed on first fixed run |
| DeepSeek V4 Flash | opencode | FAIL | 4.1m | nominal tolerance failed, max_abs_diff around 0.53 |
| DeepSeek V4 Pro | opencode | FAIL | 5.9m | first run had Triton fp8 load cast error |
| OpenCode GLM-5.1 | opencode | EARLY | 11.5m | provider early-stop/no solution on opencode route |
| Kimi K2.6 | kimi | ERR | 4s | invalid or expired API key |
| MiniMax/Qwen/MiMo via OpenRouter | opencode | ERR | 1-2s | provider_insufficient_credits |
recovery smokes
| model | route | outcome | elapsed | note |
|---|---|---|---|---|
| GLM-5.1 | zai-claude | FAIL | 11.0m | direct ZAI route worked, nominal max_abs_diff=0.5625 |
| DeepSeek V4 Pro | opencode | FAIL | 9.8m | second attempt reached verifier, nominal max_abs_diff=0.539 |
| DeepSeek V4 Flash | opencode | FAIL | 3.2m | second attempt reached verifier, nominal max_abs_diff=0.539 |
| GPT-5.5 | codex | FAIL | 8.1m | Triton resource failure: 147456B shared memory > 101376B limit |
design choices
- •One primary GPU deck (RTX PRO 6000 Blackwell), plus H100/B200 boards with the same problems.
- •A small hand-designed problem deck, not dozens of ops per GPU.
- •Real coding-agent CLIs as the harness: claude code, codex, opencode, droid, kimi, cursor, gemini-cli, grok build.
- •Unlimited agent sessions; peak_fraction grounded in physical hardware ceilings.
- •Per-cell annotations with verdict, quotes from solution.py, and implication notes.