v3
10 models · RTX 3090 + H100 + B200 · 4 difficulty levels · 2071 evaluations
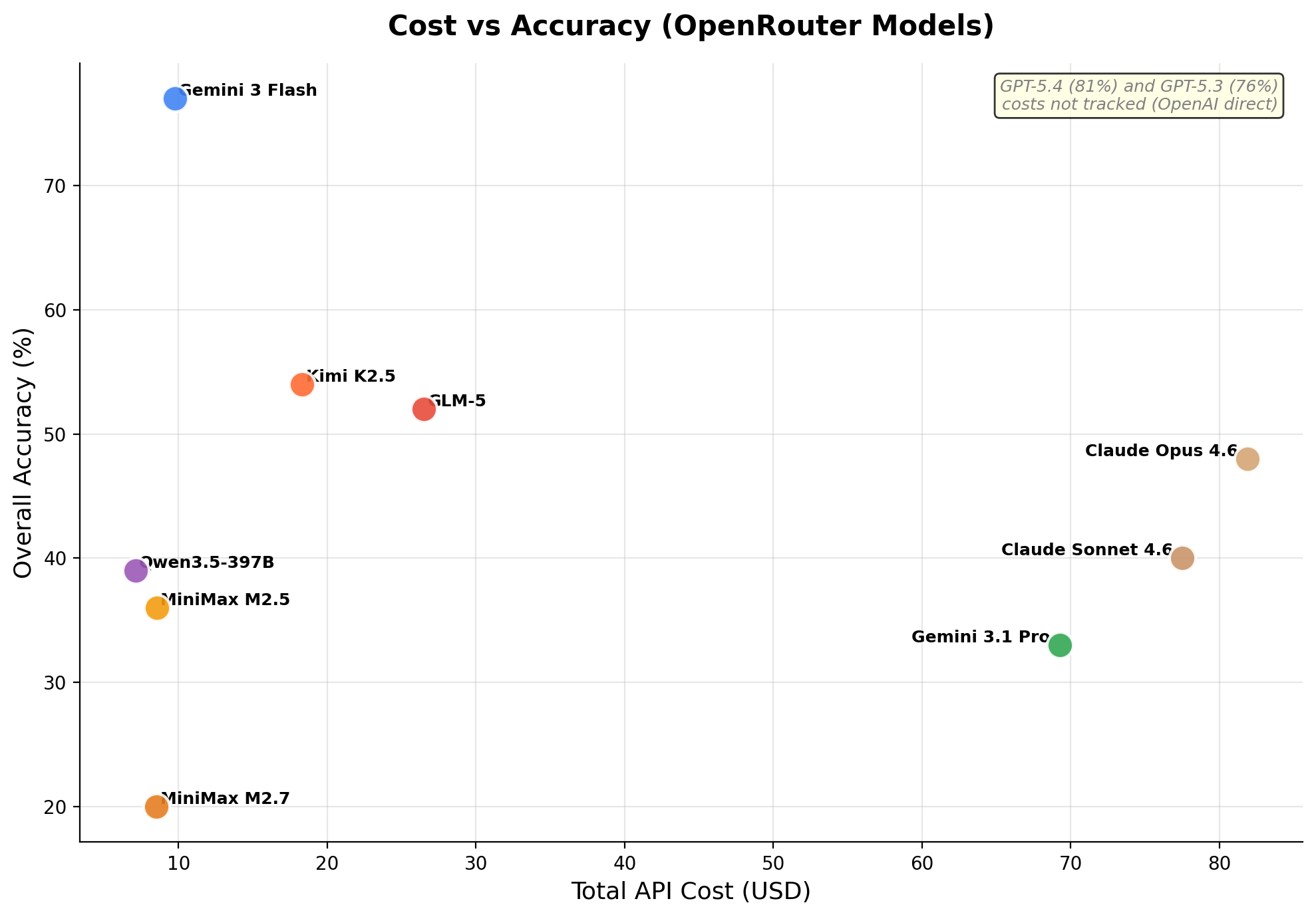
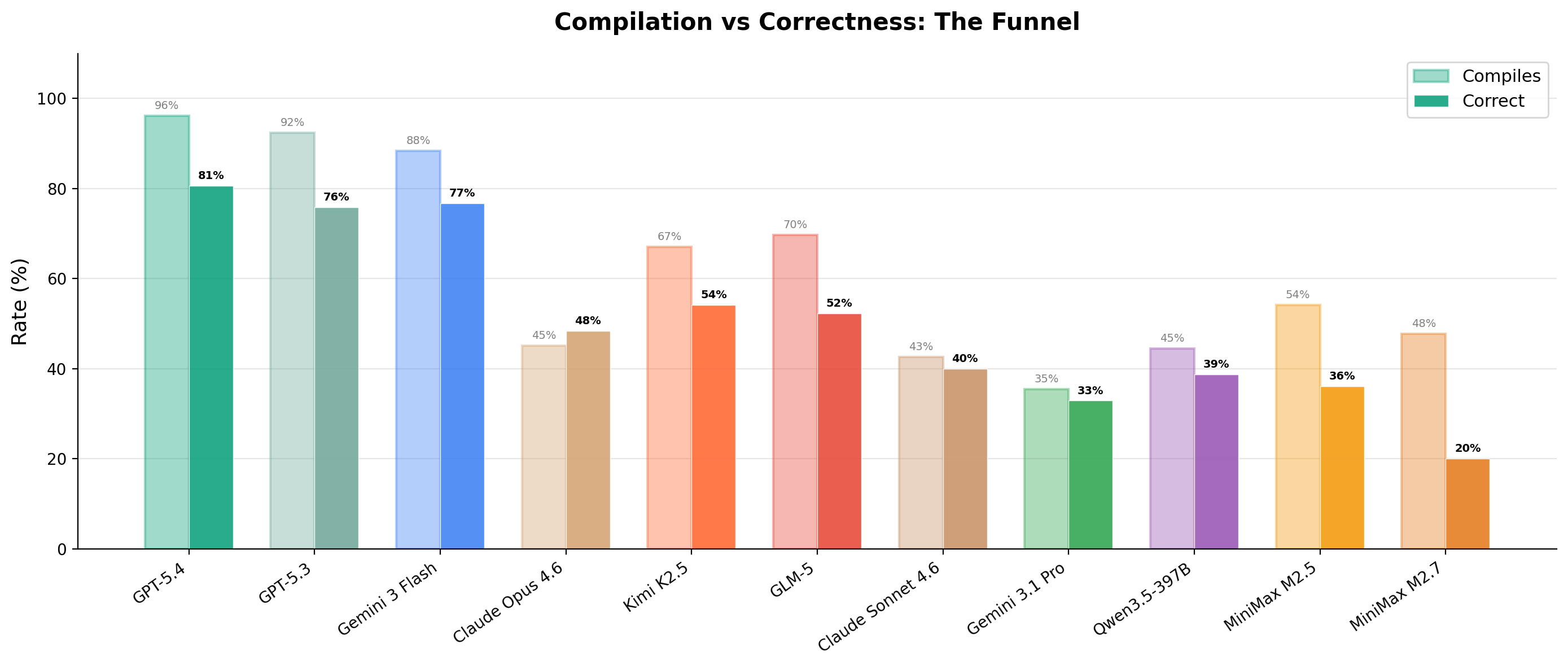
The previous-generation benchmark. After METR's “Measuring Automated Kernel Engineering” paper showed the original Stanford KernelBench was riddled with exploits (no-op kernels passing via memory aliasing, models monkey-patching torch.cuda.synchronize, constant functions like mean(softmax(x)) == 1.0), v3 was rebuilt from scratch with adaptive baselines, multi-seed correctness, modern architectures (DeepSeek MLA, MoE, FP8/INT4 GEMM, GatedDeltaNet), and tracked cost per evaluation. For more on the dev and design decisions on this bench, see the blog post.
Browse the run index for transcript viewers and run artifacts.
# results
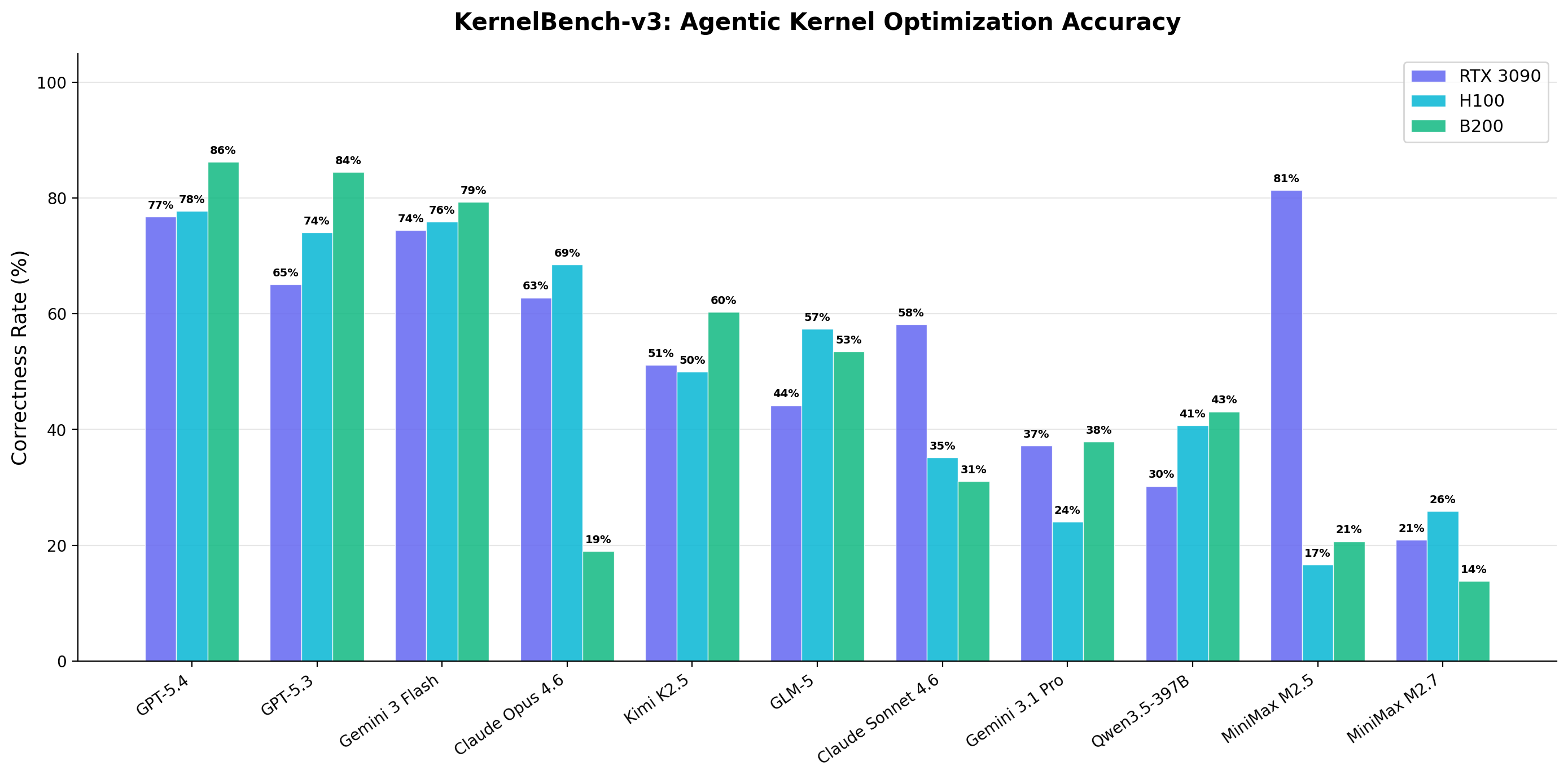
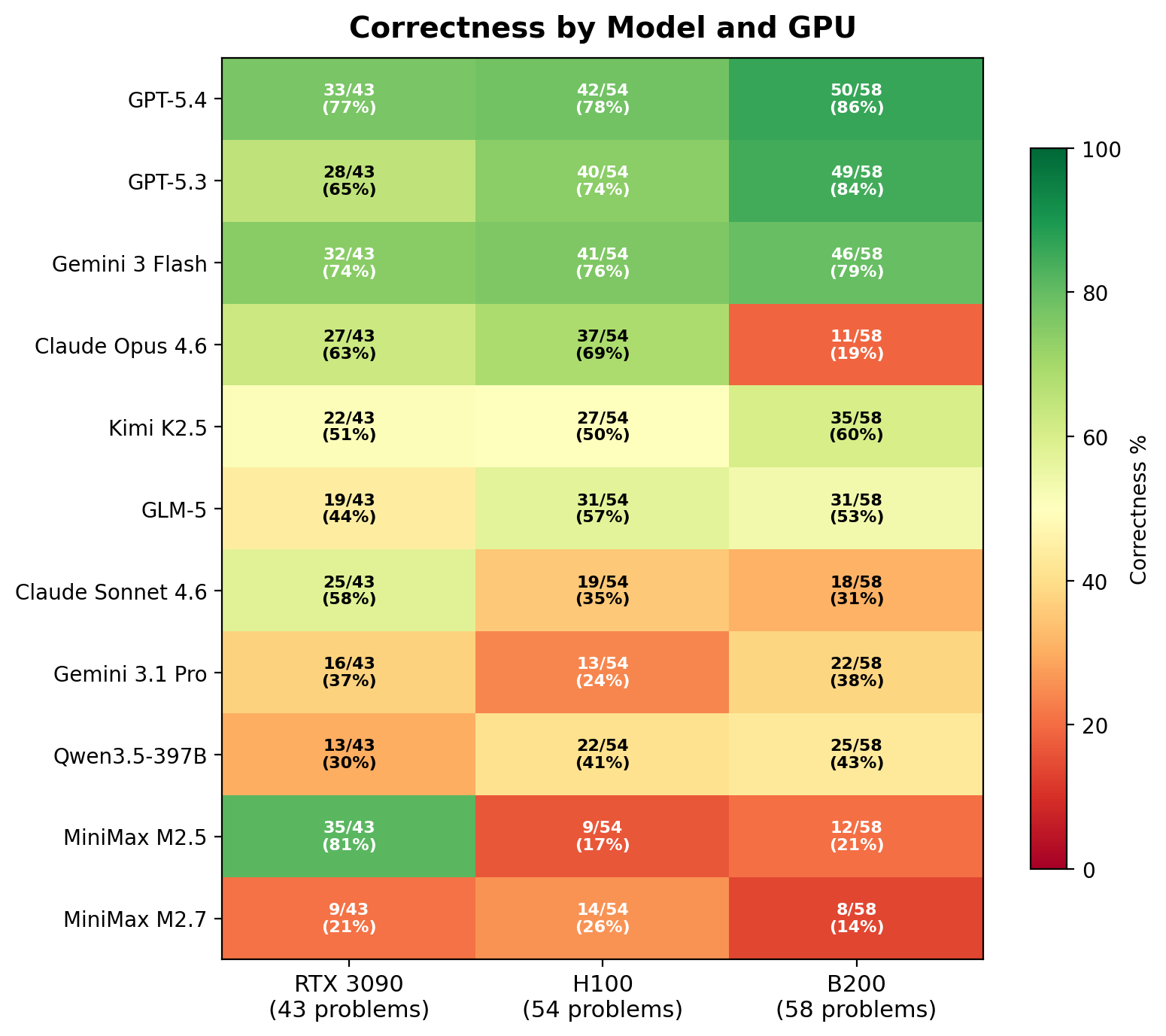
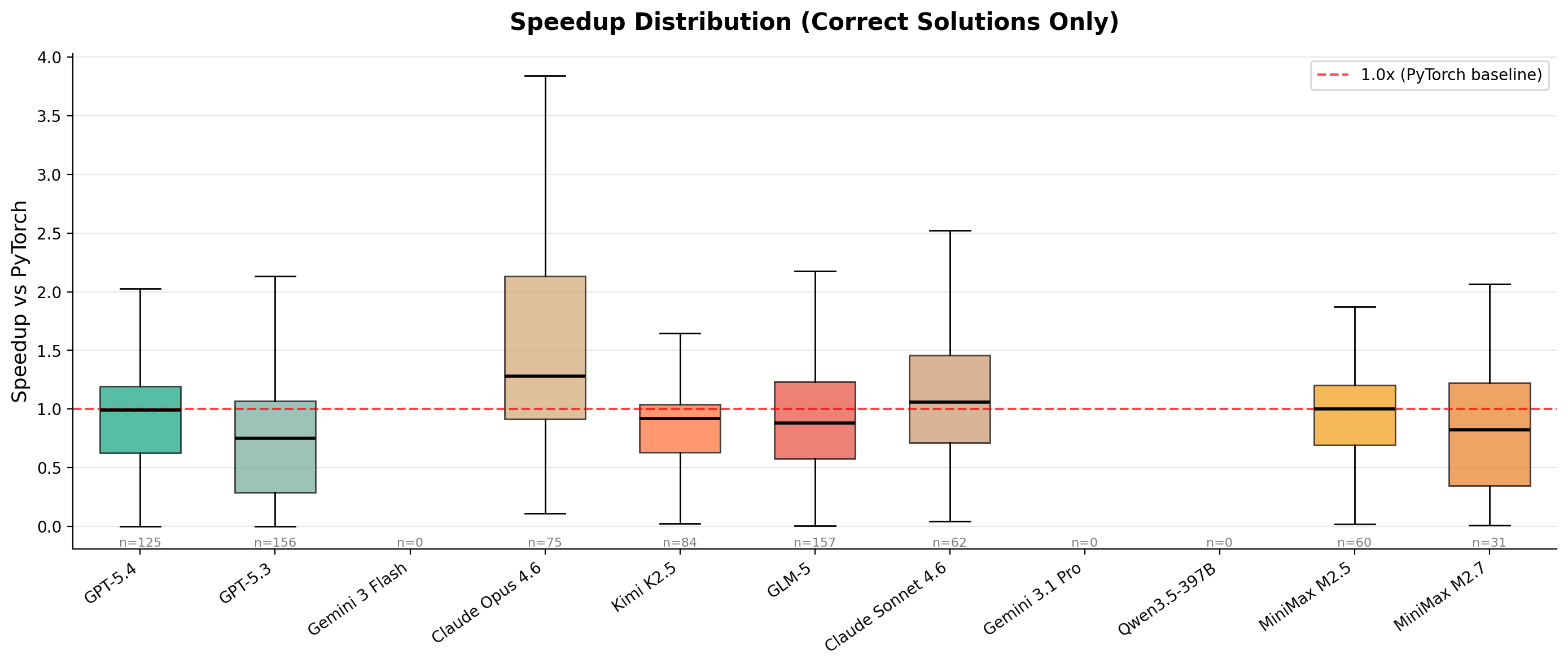
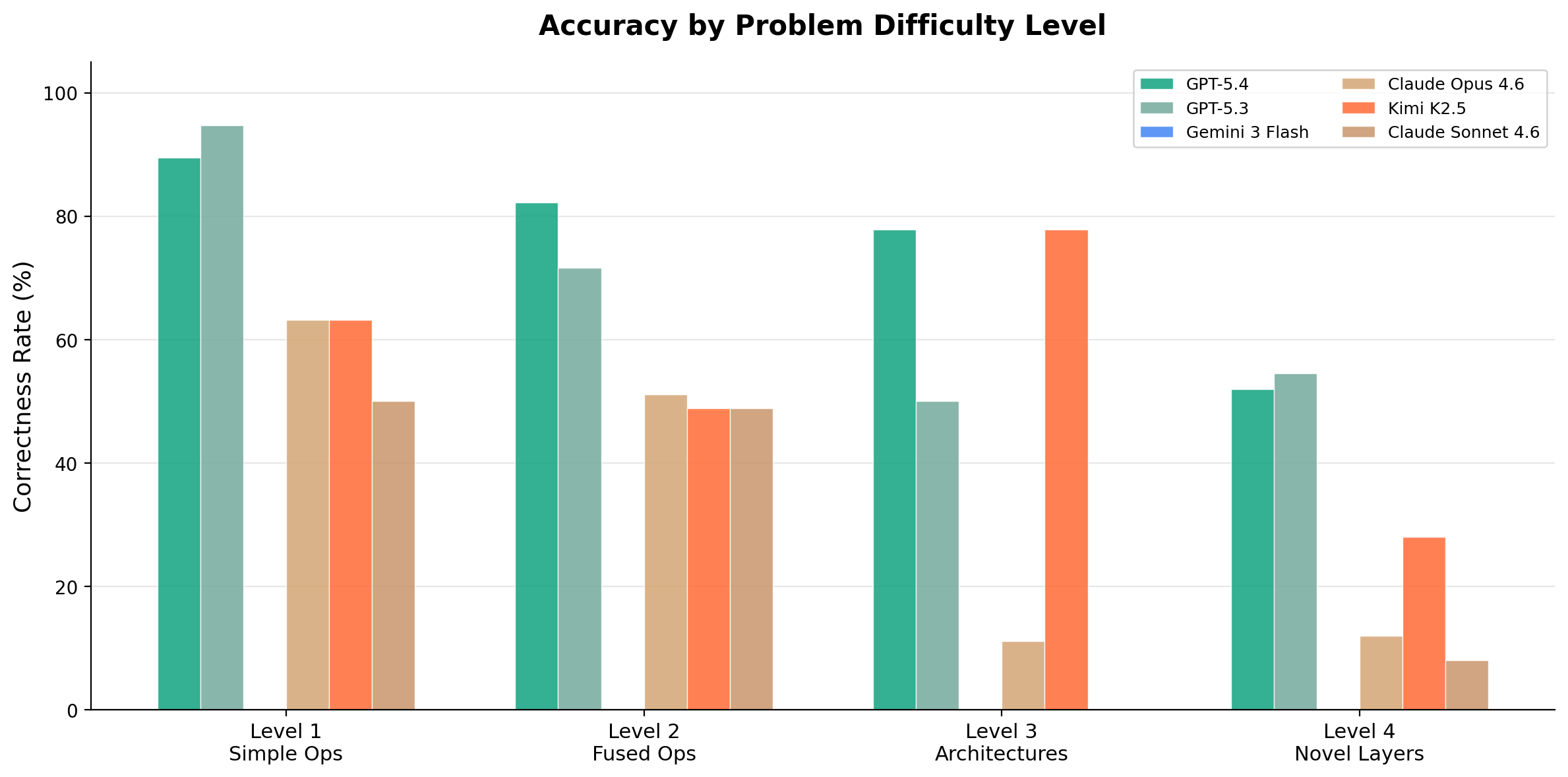
# explorer
loading...
| model ↑ | gpu | level | problem | correct | speedup | turns | total tokens | estimated cost usd | code |
|---|